Bonus Resource: Multimodal LLMs and Google Gemini
By now, you have a basic understanding of large language models (LLMs) and generative AI, so let's take a fascinating leap into Google Gemini. 😄
Launched by Google Deepmind in December 2023, Gemini made headlines for its "multimodal capabilties". Since then we've also seen the likes of GPT-4o being released. Curious about what makes multimodal LLMs stand out? Unlike traditional text-only models, these models handle a mix of data types. Let’s unravel this mystery together!
What are Multimodal Models?
Imagine an AI that understands the world not just through text but through images, audio, and more. That's what multimodal models are all about! An interesting example is the one below from Google DeepMind's paper around Google Gemini.
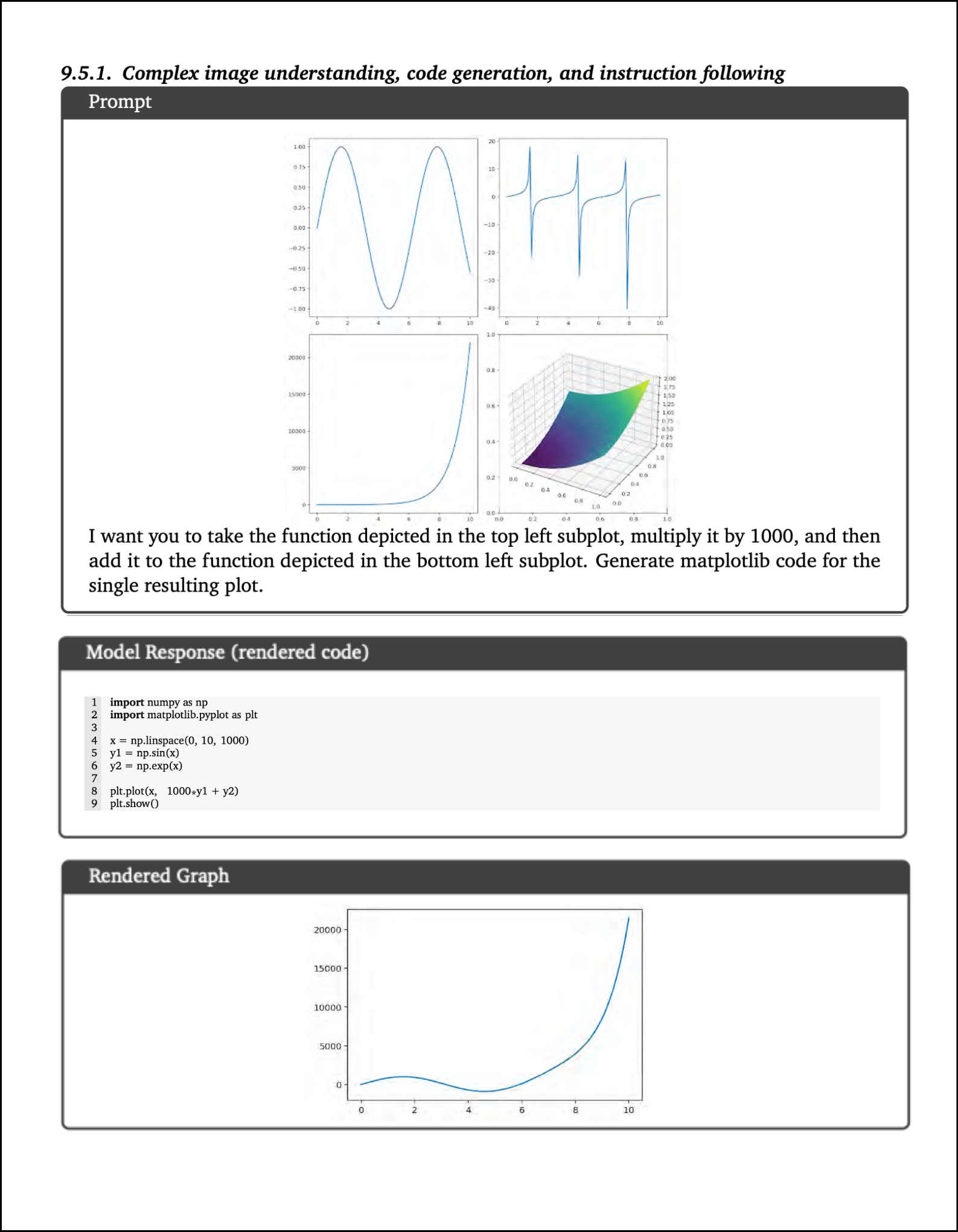
In this example, Gemini showcases its capability for inverse graphics, where it deduces the underlying code that could have produced specific plots. This process involves not only reconstructing the visual elements into code but also applying necessary mathematical transformations to accurately generate the corresponding code.
Exploring various data modalities
This section draws upon the valuable insights from an informative write-up by Chip Huyen on MLLMs. In the realm of Multimodal Large Language Models (MLLMs), we explore the fascinating world where different data types are translated and interchanged, opening up a realm of possibilities. Let's take a closer look:
Audio as Visuals: Imagine audio waves transformed into visual spectrums like mel spectrograms. This conversion offers a new perspective, making audio data visually interpretable.
Speech into Text: When we transcribe speech, we're capturing words but also losing out on nuances like the speaker's tone, volume, and pauses. It's a trade-off between capturing the literal and missing the emotional cues.
Images in Textual Form: Here's where it gets interesting. An image, in essence, can be broken down into a vector format and then represented as a sequence of text tokens. It's like translating a visual story into a textual narrative.
Videos – Beyond Moving Images: While it's common to see videos as sequences of images, this overlooks the rich layer of audio that accompanies them. Remember, in platforms like TikTok, sound is not just an add-on; it's a vital part of the experience for a majority of users.
Text as Images: Something as simple as photographing text turns it into an image. This is a straightforward but effective way of changing data modalities.
Data Tables to Visual Charts: Converting tabular data into charts or graphs transforms dry numbers into engaging visuals, enhancing understanding and insight.
Beyond these, think about the potential of other data types. If we could effectively teach models to learn from bitstrings, the foundational elements of digital data, the possibilities would be endless. Imagine a model that could seamlessly learn from any data type!
What about data types like graphs, 3D assets, or even sensory data like smell and touch (haptics)? While we haven't delved deeply into these areas yet, the future of MLLMs in these uncharted territories is both exciting and promising!
Bonus Resources: Recommended if you already know about the Encoder-Decoder Architecture
To delve deeper into the workings of Google Gemini, it's essential to understand its architecture, rooted in the encoder-decoder model. Gemini's design, though not elaborated in detail in their publications so far, appears to draw from DeepMind's Flamingo, which features separate text and vision encoders.

Note:
There is a dedicated session on Vision Transformers ahead in this bootcamp. It's included as a bonus resource along with the Transformers Architecture.
Papers for Further Reading
Last updated